
Introduction
Introduction
Selenium test automation engineers must be comfortable in locating elements in web pages. XPath and CSS are the most powerful location strategies used in Selenium as compared to other location strategies (id, name, className, linkText, partialLinkText and tagName )
Mastering XPath and/or CSS is essential for the Selenium test automation engineers to locate dynamic web elements, elements without ids or names and elements with dynamic ids and names. Tagname is not a useful location strategy to locate elements as there will be many elements with the same tagname. LinkText is only useful for the anchor <a> tags only. Also, it is not useful when the visible text changes as in multilingual systems
It is noted that most of the amateur Selenium automation engineers do not pay much attention to master location strategies. Recording and playback will not work with the applications with dynamic elements. This leads to failure of the automated test scripts (brittle) when web pages with dynamic contents are automated. Most of the testers rely on extracting the XPaths from browser plugins. These tools have limitations and do not provide the best XPath for dynamic elements.
We will discuss XPath in detail with examples and explore a few tools to generate XPaths easily.
Please refer to our blog post on Mastering CSS for Selenium Test Automation if you wish to switch to CSS.
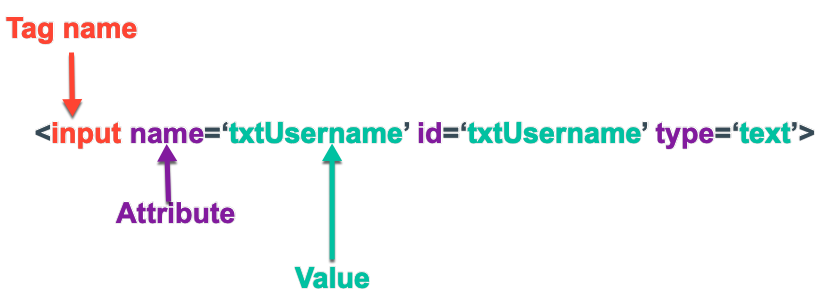
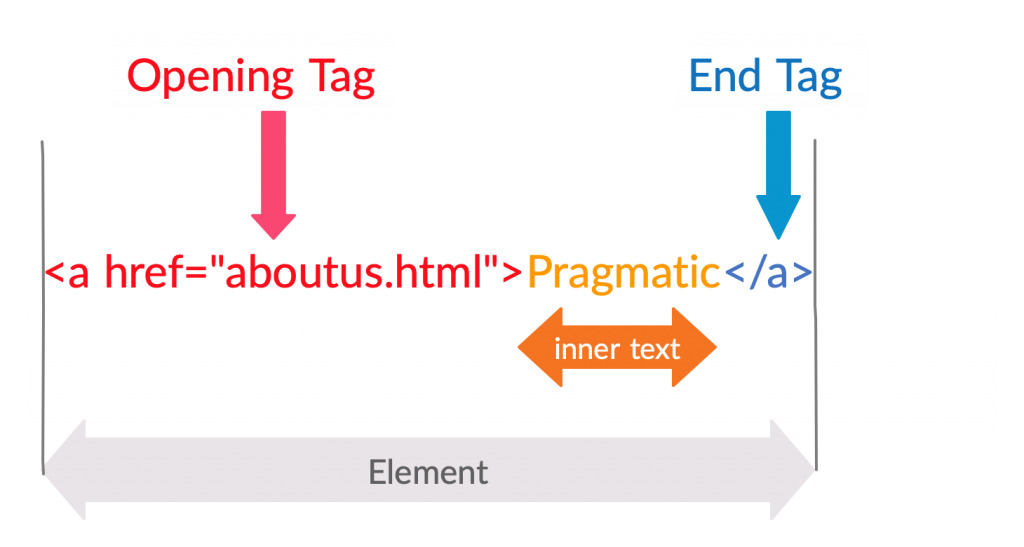
Terms used in XPath
Terms used in XPath
Lets get familiar with the basic terms used in XPath syntax.
Using XPath for locating elements in HTML
Using XPath for locating elements in HTML
We have our own way of introducing (explaining) XPath to the trainees in our public training programs.
We write following two equations. A=B and B=C. We ask the students what can be derived from these two expressions. Immediately students reply with the answer A=C, even before the question is asked :-).
Then we give following two statements
-
- XPath can be used for locating the elements in XML
- XML and HTML have similar syntax (HTML is a subset of XML)
Hence we can derive XPath can be used for locating elements in HTML pages (web pages) too . Selenium uses XPath to locate elements in web pages.
Why do we need to master many XPath syntaxes?
Why do we need to master many XPath syntaxes?
We may not be able to locate some elements using their ID or Name as some elements do not have unique attributes (id or name). Some attributes are dynamically changed. There could be elements without any attribute too. Hence we may have to locate them differently than the static elements.
XPath can be used for
-
- Locating elements with respect to a known element
- Locating elements with partially static attribute values
- Locating elements without attributes or without unique attributes
XPath can do bidirectional navigation (Going forward and backward)
XPath is one of the most flexible and strongest location strategies.
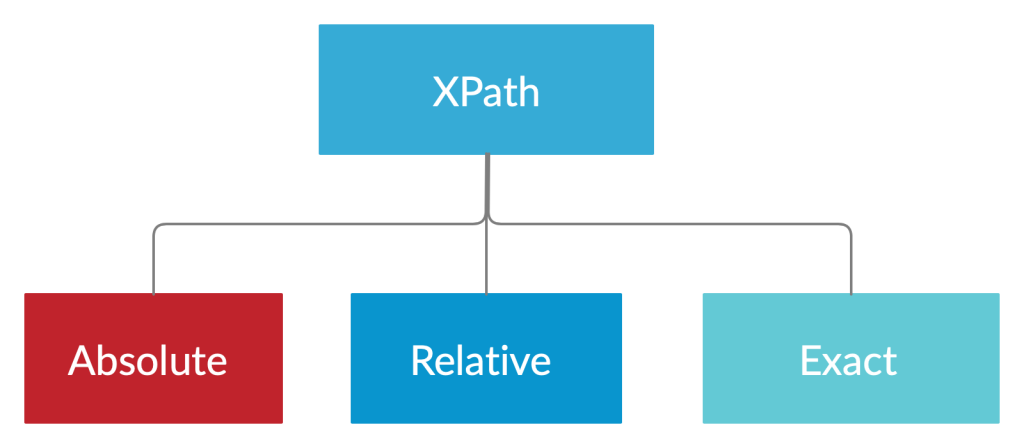
Types of XPath
Types of XPath
We have grouped XPaths into three types.
Absolute XPath
Absolute XPath
Absolute XPaths starts with the root of the HTML pages.
Absolute XPaths are not advisable for most of the time due to following reasons
- Absolute XPaths are lengthier and hence they are not readable
- Absolute XPaths are not resilient. They tend to break when minor structural changes are introduced to the web pages
Absolute XPaths shall be used only when a relative XPath cannot be constructed. (highly unlikely). It is not recommended to use absolute XPath in Selenium.
Syntax: Absolute XPaths start with /html
Example: /html/body/div[1]/div/div[2]/form/div[2]/input
Relative XPath
Relative XPath
Relative XPaths is used for locating elements with respect to a element with known (solid) XPath. The element of your choice is referred relative to a known element.
Syntax: Relative XPaths are started with two forward slashes ‘//’.
Examples :
- //div[@id=’divUsername’]/input
- //form/div[@id=’divUsername’]/input
- //form/*/input
There could be zero or more elements between the context element (starting element with a known Xpath) and the target element
Locating elements using their own tag-name, attributes , values and inner text. This is simpler and very useful if the target element has a unique way to locate it. Exact Xpath is resilient to structural changes of the web page. It is important to consider following while choosing an XPath from available options. A good locator is: When you want to locate a single element your XPath should have only one candidate element (unique). It will be easier to identify the element if it is descriptive and short(for maintainability). XPaths generated from tools may not be user-friendly. It should be possible to locate an element with given XPath when the test is run again in subsequent releases too. XPath should be selected in such a way it is valid even after changes in DOM (resilient). You will have multiple XPath options. A shorter XPath shall be selected to make it more readable in your test scripts. Following HTML (DOM) will be used for the explaining most of the XPath syntax in this post. The following syntax can be used for locating elements when at least one of the attribute’s value is unique and static. Syntax: //*[@attributeName=’value’] Let’s locate the username field in following. We have three valid XPaths Examples : Single quotations should be used to enclose the values (in Java).You need to use escape character if you wish to enclose the values with double quotes. Example : //*[@id=\”txtUsername\”]
In our real life we cannot locate a person with name Mohammed in a Muslim community. Selenium will pick the first element in the path if there are multiple candidates for a given XPath when webdriver.findElement(By.xpath(“XPATH”)) method is used. All the candidate elements can be assigned to a List when webdriver.findElements(By.xpath(“XPATH”)) method is used. Examples : Locating elements by position is discussed further in a separate section. findElement method throws NoSuchElementException error when there is no elements with given XPath. Use findElements method and check the size when working with non-present elements. Syntax: //tagName[@attributeName=’value’] Let’s consider locating the username input field again Examples :
NOTES:
Exact XPath
What should be considered when choosing an XPath?
Sample HTML code
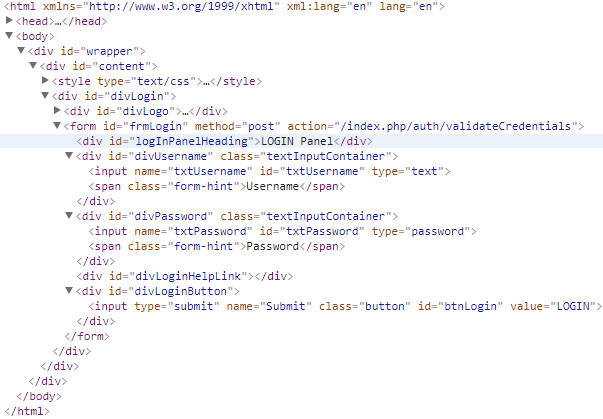
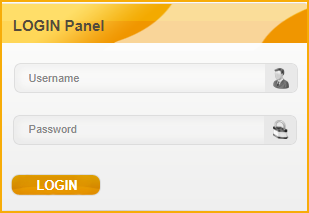 Locating an Elements with a Known Attribute
Locating an Elements with a Known Attribute

NOTE: Third XPath should not be used even though it is a valid XPath. Because It will not be a unique XPath in most of the cases. There will be many elements with type=’text’. Hence Selenium will not be able to locate the target element uniquely.
How does Selenium works when there are multiple elements (candidates) for an XPath?
Locating Elements with a Tag-name and an Attribute

This is one of the most commonly used Xpath. Most of the plugs can generate above XPaths automatically
Locating Elements with static Visible Text (exact match)
Locating Elements with static Visible Text (exact match)
Following syntax is used for locating elements containing exact text within opening tag and closing tag (inner text).
Syntax:
//tagName[text()=’exact text’] or
/*[text()=’exact text’]
Let’s consider locating following hyperlink

Examples :
- //a[text()=’Pragmatic’]
- //*[text()=’Pragmatic’]
NOTE: The inner text is case sensitive.
Locating elements by the visible text is not advisable
- If you are testing a multilingual application
- When same text is appearing in more than one location.
Locating Elements when part of the visible text is static (partial match)
Locating Elements when part of the visible text is static (partial match)
Syntax:
//tagName[contains(text(),’substring’)]
//tagName[contains(.,’substring’)]
//*[contains(text(),’substring’)]
![]()
Examples :
- //a[contains(text(),’Pragmatic’)]
- //a[contains(., ‘Test Labs‘)]
- //*[contains(text(), ‘Test Labs‘)]
Validate the XPath syntax before running the test scripts. Validating the XPath is discussed in a separate section.
Locating Elements when prefix of the inner text is static
Locating Elements when prefix of the inner text is static
You can locate the elements when part of the starting text of the inner text are static.
Syntax :
//tagName[starts-with(text(),’Prefix of Inner Text’)]
//*[starts-with(text(),’Prefix of Inner Text’’)]
![]()
Examples :
- //a[starts-with(text(),’Pragmatic’)]
- //*[starts-with(text(), ‘Prag‘)]
Locating elements with Visible text in input elements
Locating elements with Visible text in input elements
Locating input elements with visible text should not be confused with the locating elements with inner text as in above sections. Attribute value should be used for locating the visible text in input type elements.
Syntax :
- //tagName[@value=’visibleText’]

Examples :
- //input[@value=’Janesh’]
We have already discuss the process of locating elements by tag-name and an attribute.
Locating Elements with Multiple Attributes
Locating Elements with Multiple Attributes
Sometimes it may not be possible to locate an element with a single attribute uniquely as there could be more than one candidate elements with given attribute. In the real world, we have a similar scenarios. We cannot locate a person by just their first name or last name alone. We will have to use a combination of first name and last name to locate a person uniquely without making any confusion.
Similar technique is used in Selenium for locating elements when there are more than one elements with a given attribute. We will use two or more attributes together to locate an element uniquely.
Syntax :
//*[attribute1=’value1’][attribute2=’value2’]…[attributeN=’valueN’] or
//tagName[attribute1=’value1’][attribute2=’value2’]…[attributeN=’valueN’] or
//*[attribute1=’value1’ and attribute2=’value2]
//tagName[attribute1=’value1’ and attribute2=’value2]

Examples :
- //*[@type=’submit’][@value=’LOGIN’]
- //input[@class=’button’][@type=’submit’][@value=’LOGIN’][@name=’Submit’
- //*[@type=’submit’ and @value=’LOGIN’]
Locating Elements with Dynamic Attribute values
Locating Elements with Dynamic Attribute values
Following syntax could be used when a part of the attribute’s values are NOT changed. We can use the non changing value for locating the element.
Syntax :
//elementName[contains(@attributeName,’substring of the value’)] or
//*[contains(@attributeName,’substring of the value’)]
//elementName[starts-with(@attributeName,’fixed prefix of the value’)]
![]()
Examples :
- //a[contains(@href,’pragmatic’)]
- //*[contains(@href,’testlabs’)]
- //a[starts-with(@href,’pragmatic’)]
The ends-with() function is part of XPath 2.0. Most of the browsers do not support Xpath 2.0 at the time of the writing.
Locating elements relative to known element
Locating elements relative to known element
If our target elements do not have unique attribute(s) or static innerHTML, we need to locate the elements with respective to an element who has an unchanging XPath.
We do this very well in our real life. We always give direction to an unknown location with respective to a well known location (a landmark). Giving direction to your home from a well-known shop, statue, railway station etc.
XPath has thirteen (13) different axes. We will look into a subset of useful axes in this blog post which can be used with Selenium.
Your target element should be closer to the known element (context element) to make XPath shorter, resilient and readable.
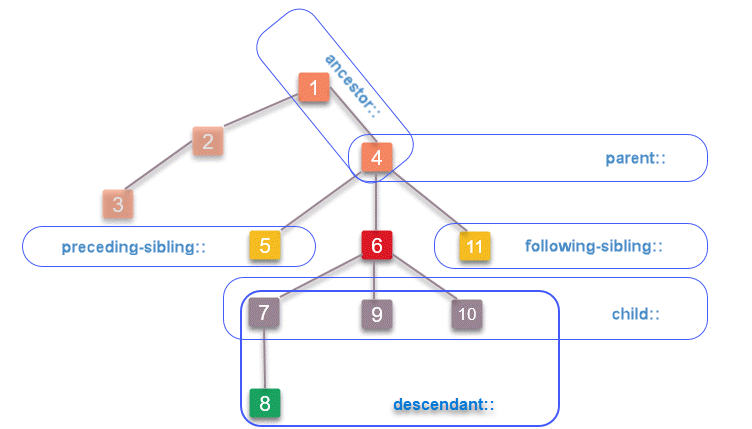
Source : XPath Expression components. http://www.iro.umontreal.ca/~lapalme/ForestInsteadOfTheTrees/HTML/ch04s01.html
Locating a parent element
Locating a parent element
The parent axis contains the parent of the context node. Every context element has only one parent element except root element (html).
Syntax :
//<knownXpath>/parent::* or
//<knownXpath>/parent::elementName
//<knownXpath>/..
Let’s see how to locate the form element with respect to the username field. We need to select an element with unchanging XPath. In this case we will take the username field.
XPath of the known element : //input[@id=’txtUsername’]

Examples :
- //input[@id=’txtUsername’]/parent::form
- //input[@id=’txtUsername’]/parent::*
- //input[@id=’txtUsername’]/..
There can be only one parent to a context (known) element. Hence specifying the element name is optional. But it is good to specify the element name for readability.
Locating a child element
Locating a child element
The child axis contains the children of the context node
Syntax :
//<xpathOfContextElement>/child::<elementName> or
//<xpathOfContextElement>/child::*
//<xpathOfContextElement>/<elementName>

Examples :
In following examples context element’s XPath is div[@id=’divUsername’]
- //div[@id=’divUsername’]/child::input
- //div[@id=’divUsername’]/input
In practice / is used instead of child:: from the known XPath.
Locating grand children
Locating grand children
Syntax :
//<xpathOfContextElement>/*/<elementName>
//<xpathOfContextElement>/child/<elementName>

Examples :
- //form/*/input
- //form/div/input
Locating ancestors of a known element
Locating ancestors of a known element
The ancestor axis contains the ancestors of the known element; ancestor axis consists of the parent of a known element and the parent’s parent so on.
Syntax :
//<xpathOfContextElement>/ancestor::<elementName> or //<xpathOfContextElement>/ancestor::*
Examples :
- //input[@id=’txtUsername’]/ancestor::form : will select the form element
- //input[@id=’txtUsername’]/ancestor::* : div element will be selected from the available candidates (div, form etc) as it comes first in the path if you use findElement method.
Locating descendants of a known element
Locating descendants of a known element
The descendant axis contains the descendants of a known element; descendant axis consists of the children of a context element and their children and so on.
Syntax :
//<xpathOfContextElement>/descendant::<elementName> or //<xpathOfContextElement>/descendant::*
Examples :
- //form[@id=’frmLogin’]/descendant::input
- //form[@id=’frmLogin’]//input
You can use // instead of descendant:: keyword to locate descendants.
Locating following elements
Locating following elements
Keyword following:: can be used for locating element(s) anywhere below the tree with respect to a known element (context element).
Syntax :
//<xpathOfContextElement>/following::<elementName> or
//<xpathOfConextElement>/following::*
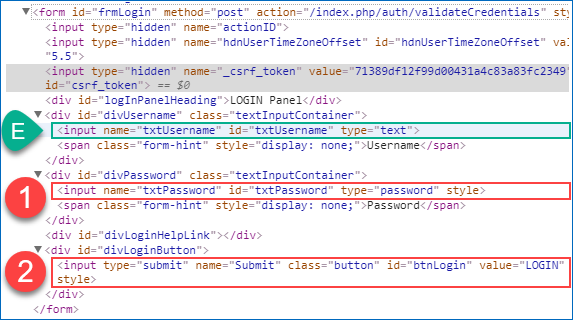
Examples :
- //input[@id=’txtUsername’]/following::input
- //input[@id=’txtUsername’]/following::*
There are two candidate elements. Any descendant elements after the first candidate in the path are excluded by Selenium when you use findElement method.
To select the login button input element with respect to the username field.
- //input[@id=’txtUsername’]/following::input[last()]
- //input[@id=’txtUsername’]/following::input[2]
Locating preceding element
Locating preceding element
Keyword preceding:: is used for locating an element before a known (XPath) element.
The preceding axis contains all nodes that are descendants of the root of the tree in which the context node is found, are not ancestors of the context node, and occur before the context node in document order
Syntax :
//<xpathOfContextElement>/preceding::<elementName> or
//<xpathOfContextElement>/preceding::*
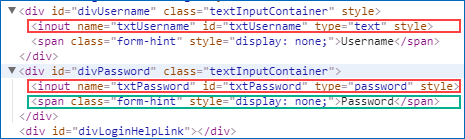
Examples :
- //span[text()=’Password’]/preceding::input
There will be two candidate elements (username and password elements). Selenium will select the password input element when findElement method is used. Elements are ordered from the context element (span).
2. //span[text()=’Password’]/preceding::input[2]
Above can be used for selecting the username field.
Locating following sibling
Locating following sibling
Keyword following-sibling:: is used to locate the element(s) comes after a context element within same HTML hierarchy. Following siblings are the elements (children) of the context node’s parent that occur after the context element in document order
Syntax :
//<xpathOfContextElement>/following-sibling::<elementName> or
//<xpathOfContextElement>/following-sibling::*
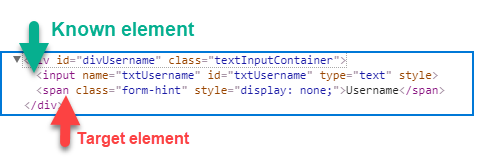
Examples :
- //*[@id=’txtUsername’]/following-sibling::span
- //*[@id=’txtUsername’]/following-sibling::*
Locating preceding sibling
Locating preceding sibling
Keyword preceding-sibling:: is used to selects the sibling(s) that comes before the context node with a known XPath, those elements (children) of the context node’s parent that occur before the context element in document order.
Syntax :
//<xpathOfKnownElement>/preceding-sibling::<elementName> or
//<xpathOfKnownElement>/preceding-sibling::*

Examples :
- //span[contains(text(),’Username’)]/preceding-sibling::input
- //span[contains(text(),’Username’)]/preceding-sibling::*
With this we complete discussion of XPath with axes. Please note that we have not discussed attribute, ancestor-or-self, descendant-or-self, namespace and self axes in this article as they do not have practical usage in the context of Selenium.
Locating Several XPaths
Locating Several XPaths
You can locate multiple elements by separating two or more XPath expressions with | character.
Syntax :
XPath1|Xpath2….|XPathN
If the first XPath is available in the first element is selected by Selenium for further actions. If both are available first one is Selected when you use findElement method. Both will be selected if you use findElements method. If only second XPath (Xpath2) is available then second element will be selected. If both of them are NOT available Selenium gives an error, NoSuchElementException when you use findElement method.
Example :
- //input[@id=’txtUsername’]|//input[@name=’txtPassword’]
In this example available elements can be located.
This is useful when you know one of them would exist when the page is loaded. - //*[@id=’txtUsername’]|//*[@name=’txtPassword’]|*[@name=’btnLogin’]
Working with Operators
Working with Operators
You can use various operators to compare numeric value in attributes and inner text. We have addition ( + ), subtraction ( – ), multiplication ( * ), division ( div ), equal ( = ), not equal ( != ), less than ( < ), less than or equal ( <= ), greater than ( > ), greater than or equal ( >= ), and, or , mod operators.
Lets see an example
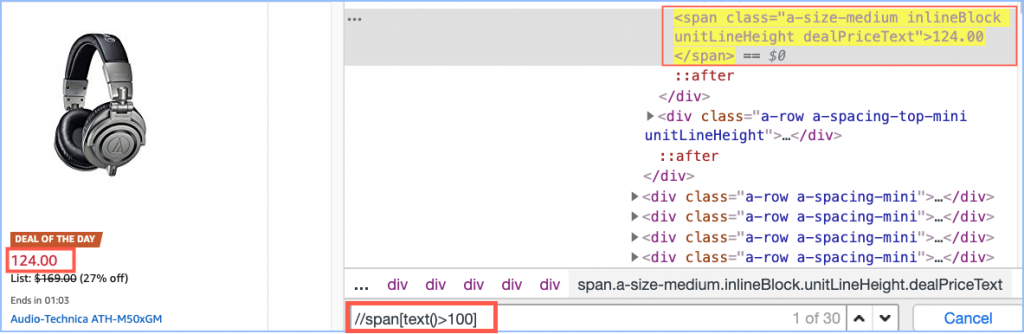
Say you need to locate element(s) with deal price greater than 100
//span[contains(@class,’dealPriceText’) and text()>100]
You can combine the techniques learned to build complex XPaths and locate any element in DOM.
Locating an element by position
Locating an element by position
Locating element by position can be used for locating an element explicitly when there are many candidate elements matching the given XPath.
Syntax :
Xpath[n] or Xpath[position()=n]
Xpath[position()>n] position() can be combined with operators
Xpath[last()]
Xpath[last()-n]
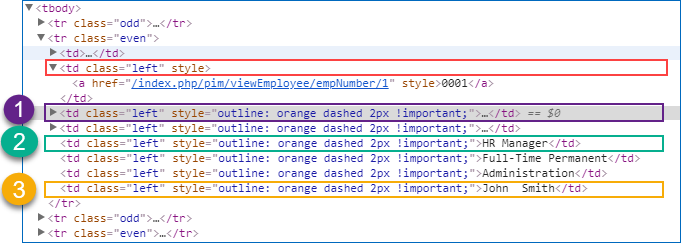
Examples :
XPath //a[text()=’0001′]/../following-sibling::td has five candidate elements. Order selectors can be used for filtering the target element(s).
- //a[text()=’0001′]/../following-sibling::td[1] or //a[text()=’0001′]/../following-sibling::td[position()=1]
- //a[text()=’0001′]/../following-sibling::td[last()-3]
- //a[text()=’0001′]/../following-sibling::td[last()]
NOTE: 1 should be used for selecting the first element from the context element .
Validating XPath
Validating XPath
It is important to ensure XPath used in your automation script is validated before running the script. Fixing the XPaths after running the test is expensive. There are many tools available to validate the correctness of the XPaths.
Tools for extracting XPaths
Tools for extracting XPaths
You can search for the extensions available in browsers (chrome, firefox) to extract the XPaths. Most of them can generate the XPath of simple elements and fail to give better XPaths for dynamic and complex elements. Most of them are longer, not user-friendly and brittle. Hence it is advisable to be comfortable in syntax of writing XPaths from scratch and validating them using a tool before using them in your tests.

Please refer to the plugins’ documentation to get most from them. Here are few extensions you can use.
- Ranorex Selocity by Ranorex [Rich feature set with user friendly interfaces]
- ChroPath by Autonomiq.io [Frequently updated]
- Chrome DevTools window
There are many browser plugins available for validating and extracting XPaths. My personal favorite is Ranorex Selocity for extracting XPath and validating the XPath syntax.
- Install Ranorex Selocity plugin from Chrome store
- Navigate to your web page
- Select the target element
- Inspect the element
- Select Ranorex Selocity in developer tool
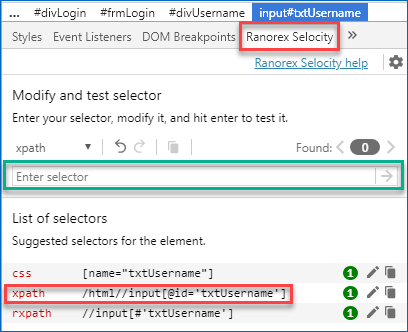
- XPath of the selected element is automatically generated
Copy XPath from Context Menu
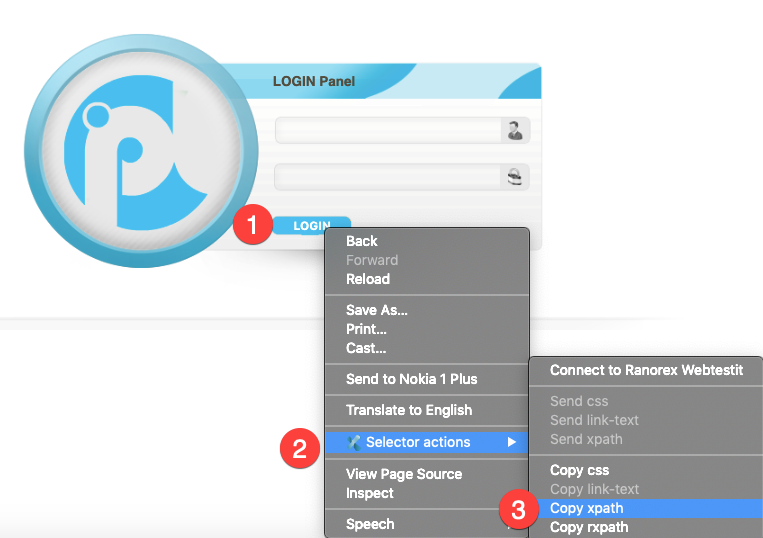
To Verify a Xpath
- Type the XPath syntax in enter selector input box
- Hit enter to verify the syntax
Following demonstrates using Ranorex Selocity for validating a XPath syntax.

XPath or CSS
XPath or CSS
CSS and XPath are the most popular, widely used and powerful location strategies within the Selenium test automation community. CSS has gained wider acceptance from the test automation engineers due to following reasons. (People in favor of CSS says)
- CSS more readable ( simpler )
- CSS is faster (especially in IE)
Those who are in favor of XPath says about its ability to transverse around the page in any direction where CSS cannot. XPath can traverse up and down the DOM. CSS can traverse only down the DOM. These claims may be already outdated :-).
Some research demonstrates that there is no significant difference in speed. Mastering both of them is a good idea for the Selenium test automation engineers who wish to build their career around Selenium. It is better to a use single location strategy for a project for a number of reasons.
Some gurus advice a hybrid approach. They use ID and name first if they are static and moving to CSS. XPath is used only when it is required.
CSS is used internally in By.id locator. CSS is the default locator in Selenium.
Following is from the API documentation.
Care should be taken when using an XPath selector with a
webdriver.WebElementas WebDriver will respect the context in the specified in the selector. For example, given the selector//div, WebDriver will search from the document root regardless of whether the locator was used with a WebElement.

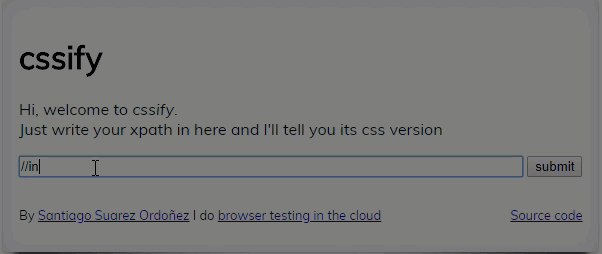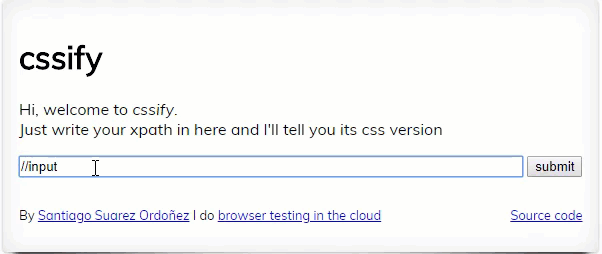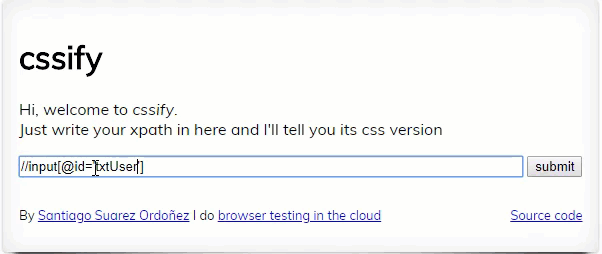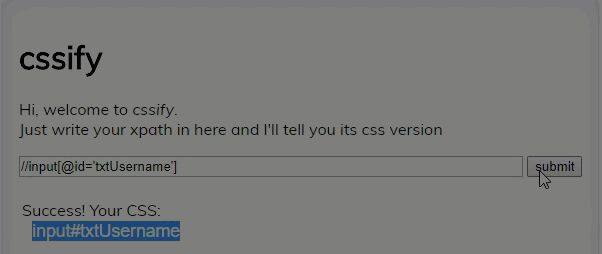
Convert your XPath to CSS
Convert your XPath to CSS
If you have decided use CSS and want to convert existing XPaths into CSS following program can be used. ccsify by Santiago Suarez Ordoñez
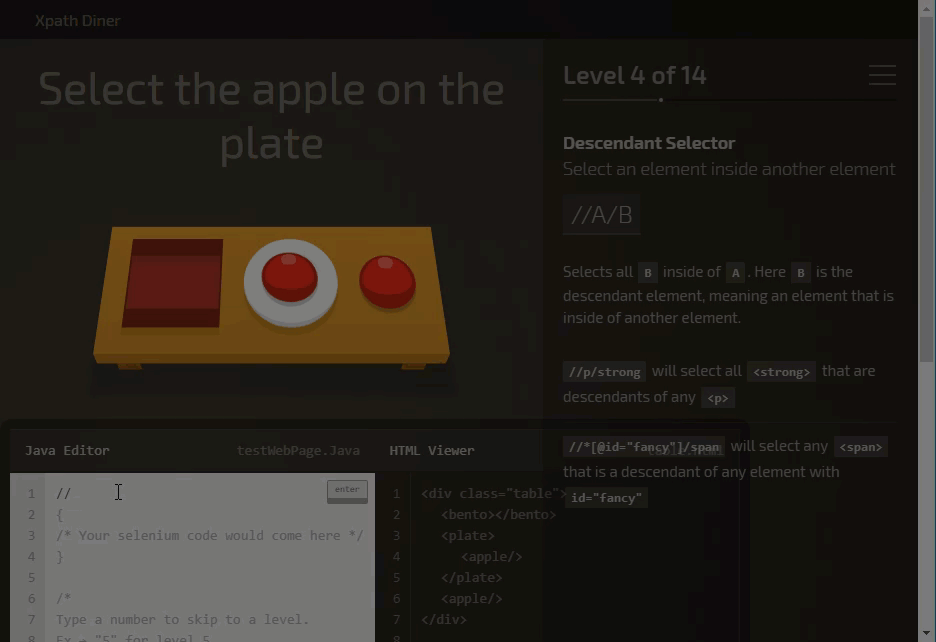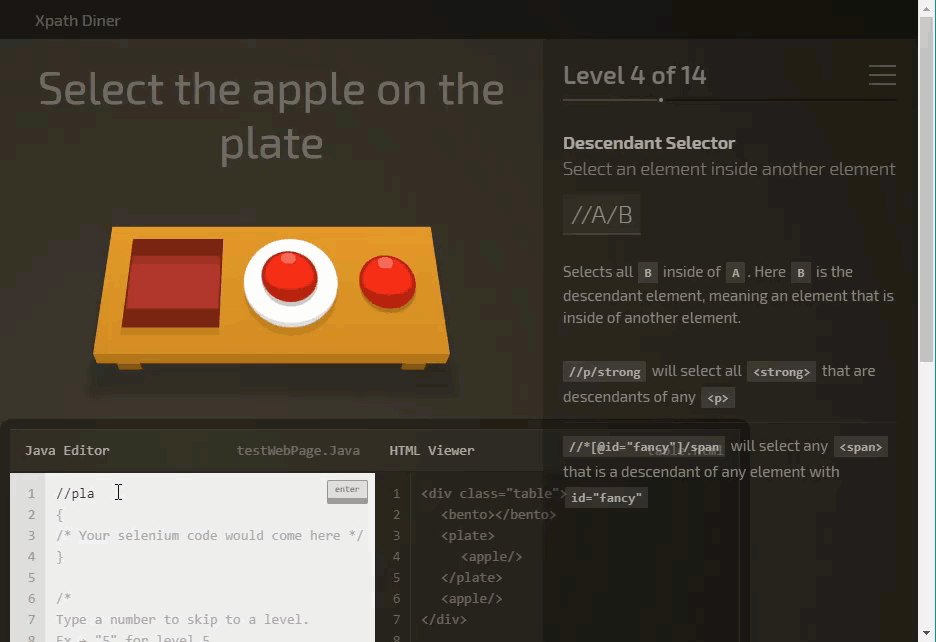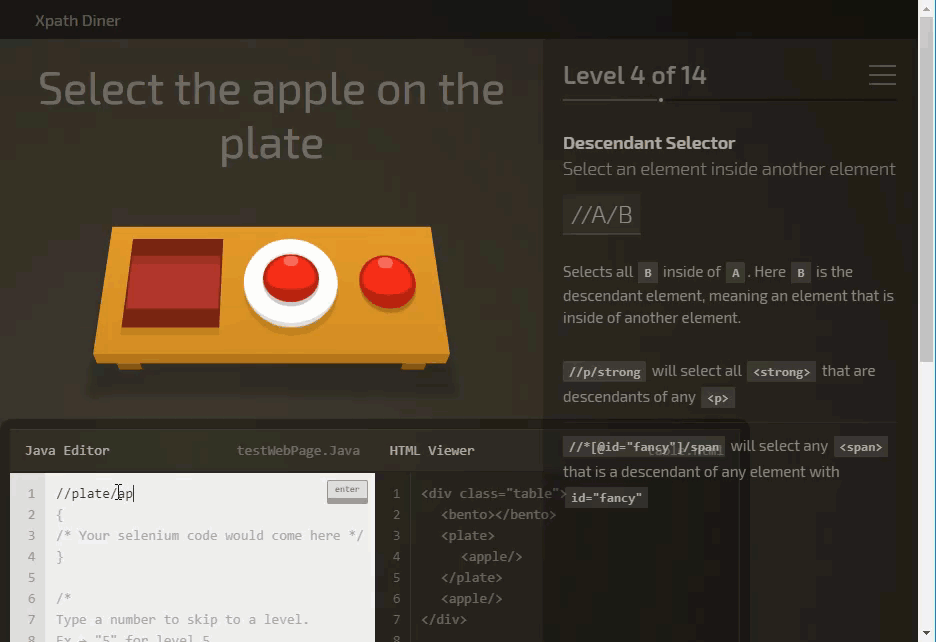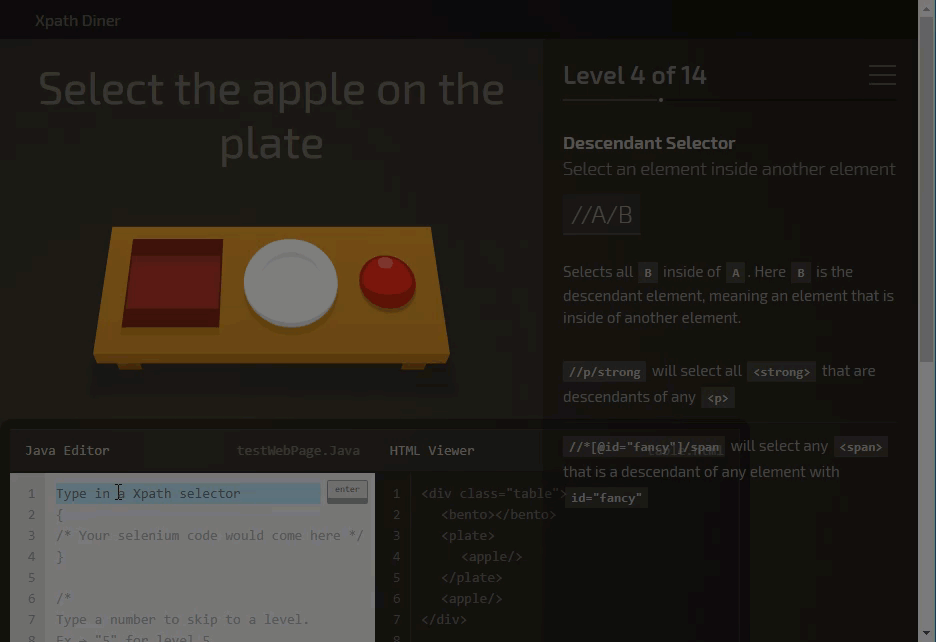
XPath game
XPath game
You can practice XPath using XPath selector game
It’s a fun game to learn and practice XPath.
Quick Reference
Quick Reference
| XPath Syntax | Note |
|---|---|
| //T[@id=’i’] | Locating Element with tag-name T and id i |
| //*[@id=’i’] | Locating element(s) with id i |
| //T[@name=’n’] | Locating Element with tag-name T with name n |
| //*[@name=’n’] | Locating element(s) with name n |
| //T[@A=’V’] | Locating Element with tag-name T with an attribute A and associated value exactly V |
| //T[contains(@A,’V’)] | Locating Element with tag-name T with attribute A containing substring of the value is V |
| //T[starts-with(@A,’V’)] | Locating Element with tag-name T with attribute A and it's value starts with V |
| //T1[@A1=’V1’] | //T2[@A2=’V2’] | Locating Element with tag-name T with attribute A1 and value V1 or Element with tag-name |
| //T[@A1=’V1’ or @A2=’V2’ ] | Locating element(s) with tag-name T with attributes A1 with value V1 or attribute A2 with value V2 |
| //T[text()=’V’ ] | Locating element with tag-name T with exact inner text V |
| /T[contains(text(),’V’) ] | Locating element with tag-name T containing inner text V |
| //T/.. //T/parent::* | Locating the parent of and element with tag-name T |
| //T[count(*)=0] | Locating elements with tag -name T who has no child elements |
| //T[count(*)=1] | Locating elements with tag -name T who has only one child element |
| //T2/following-sibling::T1 | Locating element(s) with tag-name |
| //T2/following::T1 | Locating element(s) with tag-name T following any element of type |
| //T2/preceding-sibling::T1 | Locating element(s) with tag-name |
| //T2/preceding::T1 | Locating element(s) with tag-name T1 preceding any element of type T2 |
| //T[@disabled ] //T[@disabled='true'] | Locating element(s) with tag-name T that is disabled |
| //T[not(@disabled)] //T[@disabled='false'] | Locating element(s) with tag-name T that is not disabled |
| //T[@checked ] | Locating checkbox or radio element(s) |
| //T/*[1] | Locating first child of element T |
| //T/*[last()] | Locating last child of element T |
| //T[1] | Locating first element with tag-name T |
| //T[last()] | Locating last element with tag-name T child |
| //*[2][name()=’T’] | Second child element that is an T |
| //[T>2] | Element T with value greater than 2 |
| //[T>2 and T<6] | Element T with value greater than 2 and lesser than 6 |
| //T1/*/T2 | Locate grand children with tag-name T2 of element with tag-name T1 |
Terminology
Terminology
Root element
The top most element in a document tree. It is html element in web pages.
Siblings
Elements that have the same parent as the context node
Following
All elements that appear after the context node except any descendant
Preceding
All elements that appear before the context node except any ancestors
Following Siblings
Nodes that have the same parent and appear after the context node .
Preceding Siblings
Nodes that have the same parent and appear before the context node.
Ancestors
Node’s parent, parent’s parent and so on.
Descendants
Node’s children, children’s children and so on
InnerHTML
Text between the opening tag and closing tag of an element.
DOM
Document Object Model.It defines the logical structure of HTML documents and the way HTML is accessed and manipulated.
References
References
Automationtricks.blogspot.com. . How to use functions in xpath in selenium. [online]
Available at: http://automationtricks.blogspot.com/2010/09/how-to-use-functions-in-xpath-in.html
[Accessed 30 Jan 2020].
Online Tools for Developers. (2020). Online XPath Tester. [online]
Available at: https://extendsclass.com/xpath-tester.html
[Accessed 08 Jan 2020].
Seleniumhq.github.io. (2020). Selenium API documentation [online]
Available at: https://selenium.dev/selenium/docs/api/javascript/module/selenium-webdriver/index_exports_By.html
[Accessed 05 Feb 2020].
Onion.net . W3C XPath Exercises. [online]
Available at: http://learn.onion.net/language=en/35426/w3c-xpath
[Accessed 08 Feb2020].
W3schools.com. (2020). XPath Nodes. [online]
Available at: https://www.w3schools.com/xml/xpath_nodes.asp
[Accessed 30 Jan 2020].
W3schools.com. (2020). XPath Operators. [online]
Available at: https://www.w3schools.com/xml/xpath_operators.asp
[Accessed 08 Jan 2020].
W3schools.com. (2018). XPath Syntax. [online]
Available at: https://www.w3schools.com/xml/xpath_syntax.asp
[Accessed 30 Jan 2020].
Xpath selectors – the Game!. [online]
Available at: https://topswagcode.com/xpath/
[Accessed 30 Jan 2020].
Zvon.org. (2018). XPath Tutorials. [online]
Available at: http://zvon.org/xxl/XPathTutorial/General/examples.html
[Accessed 30 Jan 2020].
Author: Janesh Kodikara
Performance Tester | JMeter Trainer | Software Testing Service Provider